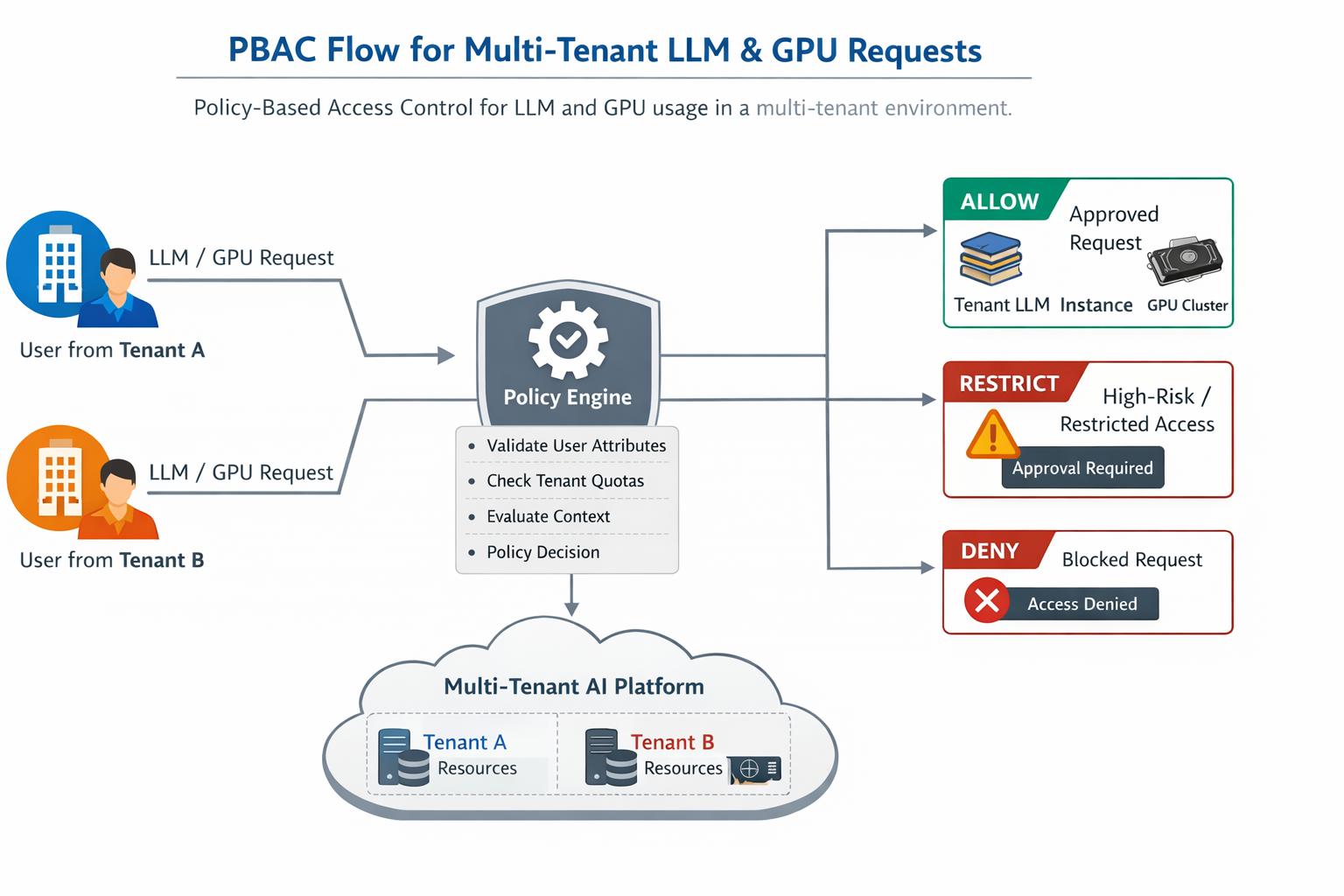
PBAC Example for Multi-Tenant LLM and GPU Usage¶
Policy Name: Multi-Tenant AI Compute & Model Access
Control Model: Policy-Based Access Control (PBAC)
In a multi-tenant platform, access to LLMs and GPU compute is governed by policies that evaluate user, tenant, resource, and context attributes at request time. Policies ensure isolation between tenants and fair resource allocation.
Policy Rules¶
-
A user may invoke a tenant LLM if:
user.tenant_id == model.tenant_id- AND
user.role ∈ {"ML Engineer", "Data Scientist"} - AND
user.cost_center == project.cost_center
-
A user may request GPU compute if:
user.tenant_id == requested.gpu_tenant_id- AND
user.training_completed == true - AND
requested.gpu_type ∈ {"A100", "H100"} - AND
requested.gpu_hours ≤ tenant.gpu_quota
-
Access is restricted when:
context.environment == "production"- AND
model.risk_level == "high" - UNLESS
user.approval_level ≥ "L3"
-
Requests are denied if:
context.time ∉ business_hours- OR
requested.cost_estimate > tenant.off_hours_limit
Example Policy Definition (YAML)¶
policy: multi-tenant-ai-usage
rules:
- effect: allow
action: invoke_model
conditions:
- user.tenant_id == model.tenant_id
- user.role in ["ML Engineer", "Data Scientist"]
- user.cost_center == project.cost_center
- effect: allow
action: request_gpu
conditions:
- user.tenant_id == requested.gpu_tenant_id
- user.training_completed == true
- requested.gpu_type in ["A100", "H100"]
- requested.gpu_hours <= tenant.gpu_quota
- effect: allow
action: invoke_model
conditions:
- context.environment == "production"
- model.risk_level == "high"
- user.approval_level >= "L3"
- effect: deny
conditions:
- context.time not_in business_hours
- requested.cost_estimate > tenant.off_hours_limit
Example Policy Definition (polar)¶
# Multi-Tenant AI Usage Policy (Deny-Overrides)
# --- Helper Rules ---
same_tenant(user, resource) if
user.tenant_id = resource.tenant_id;
role_allowed(user) if
user.role in ["ML Engineer", "Data Scientist"];
within_cost_center(user, resource) if
user.cost_center = resource.cost_center;
gpu_allowed(user, gpu) if
same_tenant(user, gpu) and
user.training_completed = true and
gpu.gpu_type in ["A100", "H100"] and
gpu.gpu_hours <= user.tenant.gpu_quota;
high_risk_allowed(user, model) if
user.context.environment = "production" and
model.risk_level = "high" and
user.approval_level >= "L3";
off_hours_violation(user, resource) if
not user.context.time in user.context.business_hours and
resource.cost_estimate > user.tenant.off_hours_limit;
# --- Deny Rules (Highest Priority) ---
deny(user, _resource) if
off_hours_violation(user, _resource);
# --- Allow Rules (Only if not denied) ---
allow(user, "invoke_model", model) if
not deny(user, model) and
same_tenant(user, model) and
role_allowed(user) and
within_cost_center(user, model);
allow(user, "request_gpu", gpu) if
not deny(user, gpu) and
gpu_allowed(user, gpu);
allow(user, "invoke_model", model) if
not deny(user, model) and
high_risk_allowed(user, model);
Enforcement¶
All requests to LLMs and GPU resources are evaluated by a central policy engine at runtime, ensuring tenant isolation, quota enforcement, and compliance with platform-wide governance rules.